
Microsoft
Microsoft AI-102
305+ Practice Questions with AI-Verified Answers
Designing and Implementing a Microsoft Azure AI Solution
AI-Powered
Triple AI-Verified Answers & Explanations
Every Microsoft AI-102 answer is cross-verified by 3 leading AI models to ensure maximum accuracy. Get detailed per-option explanations and in-depth question analysis.
Exam Domains
Practice Questions
DRAG DROP - You have 100 chatbots that each has its own Language Understanding model. Frequently, you must add the same phrases to each model. You need to programmatically update the Language Understanding models to include the new phrases. How should you complete the code? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:
var phraselistId = await client.Features.______
(appId, versionId, new ______
You need to build a chatbot that meets the following requirements: ✑ Supports chit-chat, knowledge base, and multilingual models ✑ Performs sentiment analysis on user messages ✑ Selects the best language model automatically What should you integrate into the chatbot?
You are building a Language Understanding model for an e-commerce platform. You need to construct an entity to capture billing addresses. Which entity type should you use for the billing address?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You build a language model by using a Language Understanding service. The language model is used to search for information on a contact list by using an intent named FindContact. A conversational expert provides you with the following list of phrases to use for training. ✑ Find contacts in London. ✑ Who do I know in Seattle? ✑ Search for contacts in Ukraine. You need to implement the phrase list in Language Understanding. Solution: You create a new intent for location. Does this meet the goal?
HOTSPOT - You need to create a new resource that will be used to perform sentiment analysis and optical character recognition (OCR). The solution must meet the following requirements: ✑ Use a single key and endpoint to access multiple services. ✑ Consolidate billing for future services that you might use. ✑ Support the use of Computer Vision in the future. How should you complete the HTTP request to create the new resource? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
Want to practice all questions on the go?
Download Cloud Pass — includes practice tests, progress tracking & more.
You successfully run the following HTTP request. POST https://management.azure.com/subscriptions/18c51a87-3a69-47a8-aedc-a54745f708a1/resourceGroups/RG1/providers/ Microsoft.CognitiveServices/accounts/contoso1/regenerateKey?api-version=2017-04-18 Body{"keyName": "Key2"} What is the result of the request?
HOTSPOT - You plan to deploy a containerized version of an Azure Cognitive Services service that will be used for text analysis. You configure https://contoso.cognitiveservices.azure.com as the endpoint URI for the service, and you pull the latest version of the Text Analytics Sentiment Analysis container. You need to run the container on an Azure virtual machine by using Docker. How should you complete the command? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
docker run --rm -it -p 5000:5000 --memory 8g --cpus 1 \ ______ \
Eula=accept \ Billing= ______ \
DRAG DROP - You are developing a photo application that will find photos of a person based on a sample image by using the Face API. You need to create a POST request to find the photos. How should you complete the request? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:
POST {Endpoint}/face/v1.0/______
"mode": "______"
HOTSPOT - You develop an application that uses the Face API. You need to add multiple images to a person group. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
using (______ t = File.OpenRead(imagePath))
await faceClient.PersonGroupPerson.______(personGroupId, personId, t);
HOTSPOT - You are developing an application that will use the Computer Vision client library. The application has the following code.
public async TaskAnalyzeImage(ComputerVisionClient client, string localImage)
{
List features = new List()
{
VisualFeatureTypes.Description,
VisualFeatureTypes.Tags,
};
using (Stream imageStream = File.OpenRead(localImage))
{
try
{
ImageAnalysis results = await client.AnalyzeImageInStreamAsync(imageStream, features);
foreach (var caption in results.Description.Captions)
{
Console.WriteLine($"{caption.Text} with confidence {caption.Confidence}");
}
foreach (var tag in results.Tags)
{
Console.WriteLine($"{tag.Name} {tag.Confidence}");
}
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
}
}
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:
The code will perform face recognition.
The code will list tags and their associated confidence.
The code will read a file from the local file system.
You deploy a web app that is used as a management portal for indexing in Azure Cognitive Search. The app is configured to use the primary admin key. During a security review, you discover unauthorized changes to the search index. You suspect that the primary access key is compromised. You need to prevent unauthorized access to the index management endpoint. The solution must minimize downtime. What should you do next?
HOTSPOT - You are building a chatbot that will provide information to users as shown in the following exhibit.
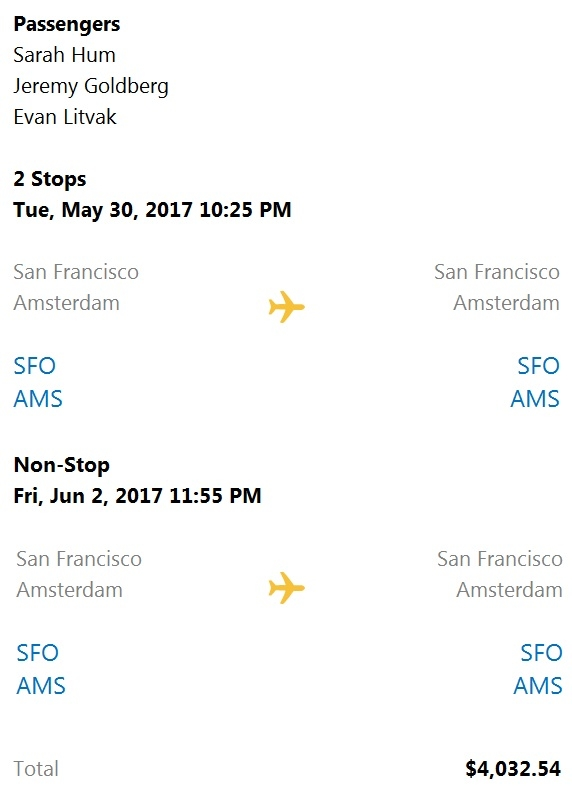
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic. NOTE: Each correct selection is worth one point. Hot Area:
The chatbot is showing ______.
The card includes ______.
HOTSPOT - You are reviewing the design of a chatbot. The chatbot includes a language generation file that contains the following fragment.
Greet(user)
- ${Greeting()}, ${user.name} For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:
${user.name} retrieves the user name by using a prompt.
Greet() is the name of the language generation template.
${Greeting()} is a reference to a template in the language generation file.
DRAG DROP - You are developing a call to the Face API. The call must find similar faces from an existing list named employeefaces. The employeefaces list contains 60,000 images. How should you complete the body of the HTTP request? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:
"______": "employeefaces",
"mode": "______"
HOTSPOT - You are developing a text processing solution. You develop the following method.
static void GetKeyPhrases(TextAnalyticsClient textAnalyticsClient, string text)
{
var response = textAnalyticsClient.ExtractKeyPhrases(text);
Console.WriteLine("Key phrases:");
foreach (string keyphrase in response.Value)
{
Console.WriteLine($"\t{keyphrase}");
}
}
You call the method by using the following code. GetKeyPhrases(textAnalyticsClient, "the cat sat on the mat"); For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:
The call will output key phrases from the input string to the console.
The output will contain the following words: the, cat, sat, on, and mat.
The output will contain the confidence level for key phrases.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You build a language model by using a Language Understanding service. The language model is used to search for information on a contact list by using an intent named FindContact. A conversational expert provides you with the following list of phrases to use for training. ✑ Find contacts in London. ✑ Who do I know in Seattle? ✑ Search for contacts in Ukraine. You need to implement the phrase list in Language Understanding. Solution: You create a new pattern in the FindContact intent. Does this meet the goal?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You develop an application to identify species of flowers by training a Custom Vision model. You receive images of new flower species. You need to add the new images to the classifier. Solution: You add the new images, and then use the Smart Labeler tool. Does this meet the goal?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You develop an application to identify species of flowers by training a Custom Vision model. You receive images of new flower species. You need to add the new images to the classifier. Solution: You add the new images and labels to the existing model. You retrain the model, and then publish the model. Does this meet the goal?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You develop an application to identify species of flowers by training a Custom Vision model. You receive images of new flower species. You need to add the new images to the classifier. Solution: You create a new model, and then upload the new images and labels. Does this meet the goal?
HOTSPOT - You are developing a service that records lectures given in English (United Kingdom). You have a method named AppendToTranscriptFile that takes translated text and a language identifier. You need to develop code that will provide transcripts of the lectures to attendees in their respective language. The supported languages are English, French, Spanish, and German. How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
var lang = new List<string> ______
using var recognizer = new ______ (config, audioConfig);
Other Microsoft Certifications












Start Practicing Now
Download Cloud Pass and start practicing all Microsoft AI-102 exam questions.
Get the app