
Practice Test #4
Simulate the real exam experience with 50 questions and a 120-minute time limit. Practice with AI-verified answers and detailed explanations.
AI-Powered
Triple AI-Verified Answers & Explanations
Every answer is cross-verified by 3 leading AI models to ensure maximum accuracy. Get detailed per-option explanations and in-depth question analysis.
Practice Questions
Your retail analytics team has an IoT gateway that uploads a 5 MB CSV summary every 10 minutes to a Cloud Storage bucket gs://retail-iot-summaries-prod. Upon each successful upload, you must notify a downstream pipeline via the Pub/Sub topic projects/acme/topics/iot-summaries so a Dataflow job can start. You want a solution that requires the least development and operational effort, introduces no additional compute to manage, and can be set up within 1 hour; what should you do?
Your startup manages 3,000 smart vending machines that publish 4 KB JSON telemetry to a Pub/Sub topic at an average rate of 600 messages per second (peaks up to 1,200). You must parse each message and persist it for analytics with end-to-end latency under 45 seconds, and each message must be processed exactly once to avoid double-counting transactions. You want the cheapest and simplest fully managed approach with minimal operations overhead and cannot maintain clusters or build custom deduplication workflows. What should you do?
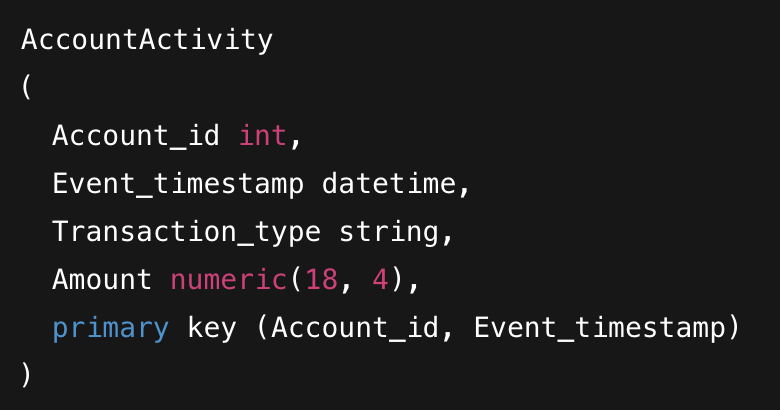
You are migrating a MySQL table named AccountActivity to Cloud Bigtable. The table schema includes Account_id, Event_timestamp, Transaction_type, and Amount, with a primary key defined as (Account_id, Event_timestamp). To ensure efficient data modeling and query performance in Bigtable, how should you design the row key?
You are a developer at a nationwide logistics platform. The company operates an on-premises dispatch system backed by PostgreSQL to store driver profiles and delivery logs. As part of a migration to Google Cloud, your team will move driver profile data to Cloud Firestore while delivery logs will also be stored in Firestore going forward. The system has 120,000 active drivers; each driver can create up to 200 delivery log entries per day from mobile devices that must support offline sync and per-driver access control. You also need efficient per-driver queries and occasional analytics that query across all drivers' logs. You are tasked with designing the Firestore collections. What should you do?
Your team uses Cloud Build to build a single container image and push it to Artifact Registry with two tags: latest and v2.3.7. You then use Google Cloud Deploy to promote this image through three GKE environments in different regions: dev (us-central1), staging (europe-west1), and prod (asia-northeast1). Compliance requires that the exact same binary is deployed to all three environments over the release week, even if tags are moved or new images are pushed. How should you reference the image in the Cloud Deploy/Skaffold release configuration to guarantee the same image is used across all environments?
Want to practice all questions on the go?
Download Cloud Pass — includes practice tests, progress tracking & more.
Your online ticketing platform runs a payment-validation microservice on a Compute Engine Managed Instance Group (autoscaling between 3 and 10 VMs) behind an internal HTTP(S) Load Balancer; during a canary at 5,000 requests per minute, 1–2% of requests intermittently return HTTP 500 when the code path handling 3-D Secure callbacks is executed, and you need to observe the values of customerId and tokenExpiry at line 214 every time that branch is hit across all running instances over the next 4 hours, with the observations written to Cloud Logging, without modifying code, restarting VMs, or redeploying. Which tool should you use?
You operate a Go-based Cloud Functions (2nd gen) HTTP function in us-central1 that processes invoice files at roughly 200 requests per second. The function must read and write objects in a single Cloud Storage bucket named acct-prod-uploads within the same project (retail-prod-123). You must follow the principle of least privilege and avoid project-wide roles and default service accounts. What should you do?
You are developing a local analytics worker that aggregates readings from 50 factory sensors at 10 Hz and publishes normalized events to a Pub/Sub topic named telemetry-normalized; you build locally 8–10 times per day and need each build to validate Pub/Sub integration in under 2 minutes without internet access or incurring any Google Cloud charges, using a dev project ID of plant-dev-31415—how should you configure local testing?
You are the lead developer for a real-time fleet tracking service running on Cloud Run at a transportation company with strict uptime SLAs. Binary Authorization for Cloud Run is enforced as an organization policy with a single attestor, and all service images are normally attested through the CI/CD pipeline. Deployments are allowed only during a 45-minute change window starting at 02:15 local time. A zero-day vulnerability in a widely used library is being actively exploited, and you must deploy a patched image immediately, before the next change window. You have built the new image and received written approval from your director via the company ticketing system. What should you do?
Your company is building a serverless QR-code rendering API on Cloud Run to generate boarding passes. The API must read PDF templates stored in a private Cloud Storage bucket named tickets-secure-prod in europe-west1, and the security team requires that: (1) production buckets must never be publicly accessible, (2) production workloads must not run with default service accounts, and (3) the API needs only read access to objects; peak traffic is 250 requests per second and clients will never access the bucket directly. You need to grant the API permission to read the templates while following Google-recommended best practices and the security constraints; what should you do?
Success Stories(6)
Study period: 2 months
The scenarios in this app were extremely useful. The explanations made even the tricky deployment questions easy to understand. Definitely worth using.
Study period: 2 months
The questions weren’t just easy recalls — they taught me how to approach real developer scenarios. I passed this week thanks to these practice sets.
Study period: 1 month
1개월 구독하니 빠르게 풀어야 한다는 강박이 생기면서 더 열심히 공부하게 됐던거 같아요. 다행히 문제들이 비슷해서 쉽게 풀 수 있었네요
Study period: 1 month
이 앱의 문제들과 실제 시험 문제들이 많이 비슷해서 쉽게 풀었어요! 첫 시험만에 합격하니 좋네요 굿굿
Study period: 1 month
I prepared for three weeks using Cloud Pass and the improvement was huge. The difficulty level was close to the real Cloud Developer exam, and the explanations helped me fill in my knowledge gaps quickly.

Start Practicing Now
Download Cloud Pass and start practicing all Google Professional Cloud Developer exam questions.
Get the app